阿里云开源Qwen2:正在训练更大的模型,下一步做多模态
发布日期:2024-09-19 19:19
来源类型:猪八戒网 | 作者:大卫·斯特雷泽恩
| 【494949澳门今晚开什么】 【2024新澳免费资料】 【六开彩澳门开奖结果查询】 | 【澳门金牛版正版资料大全免费】 【新澳开奖记录今天结果】 【2024年新澳门王中王资料】 【管家婆最准一肖一码】 【新澳彩开奖结果查询】 【2004新澳门天天开好彩大全】 【4949澳门免费资料大全特色】 【2024今晚澳门特马开什么号】 【2024年新奥资料免费精准】 【2O24澳彩管家婆资料传真】

经过数月的努力,阿里云今天发布了Qwen2,包括:
5个尺寸的预训练和指令微调模型:Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B以及Qwen2-72B; 在中文英语的基础上,训练数据中增加了27种语言相关的高质量数据; 多个评测基准上的领先表现; 代码和数学能力显著提升; 增大了上下文长度支持,最高达到128K tokens(Qwen2-72B-Instruct)。目前,Qwen2已在Hugging Face和ModelScope上同步开源。以下是核心信息:
//
1.模型基础信息
Qwen2系列包含5个尺寸的预训练和指令微调模型,其中包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B。
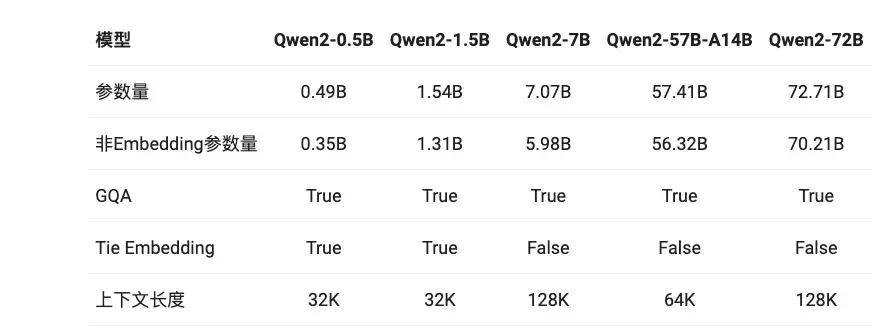
在Qwen1.5系列中,只有32B和110B的模型使用了GQA。这一次,所有尺寸的模型都使用了GQA,以便让大家体验到GQA带来的推理加速和显存占用降低的优势。
针对小模型,由于embedding参数量较大,Qwen2使用了tie embedding的方法让输入和输出层共享参数,增加非embedding参数的占比。
上下文长度方面,所有的预训练模型均在32K tokens的数据上进行训练,其在128K tokens时依然能在PPL评测中取得不错的表现。然而,对指令微调模型而言,除PPL评测之外还需要进行大海捞针等长序列理解实验。在该表中,根据大海捞针实测结果,列出了各个指令微调模型所支持的最大上下文长度。而在使用YARN这类方法时,Qwen2-7B-Instruct和Qwen2-72B-Instruct均实现了长达128K tokens上下文长度的支持。
Qwen团队投入了大量精力研究如何扩展多语言预训练和指令微调数据的规模并提升其质量,从而提升模型的多语言能力。尽管大语言模型本身具有一定的泛化性,Qwen还是针对性地对除中英文以外的27种语言进行了增强:
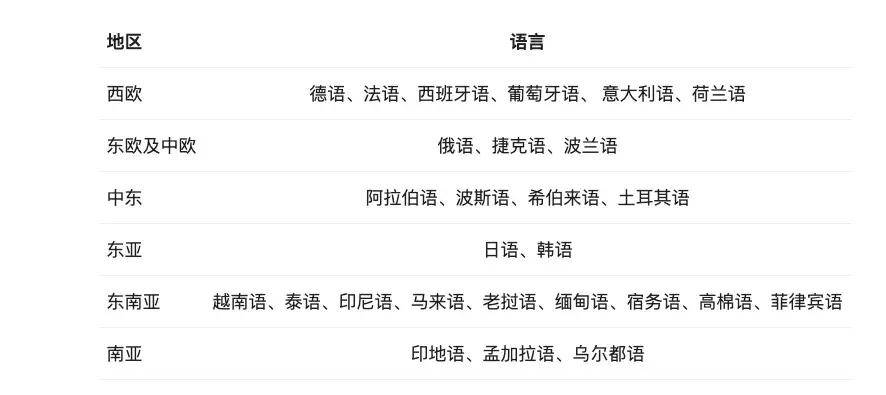
此外,Qwen2针对性地优化了多语言场景中常见的语言转换(code switch)问题,模型当前发生语言转换的概率大幅度降低。使用容易触发语言转换现象的提示词进行测试,观察到Qwen2系列模型在此方面能力的显著提升。
2.模型评测
Qwen2发布后两小时,Hugging Face联合创始人兼首席执行官克莱门特·德朗格(Clément Delangue)发推宣布,HF开源大模型榜单新的第一出来了,Qwen2-72B。
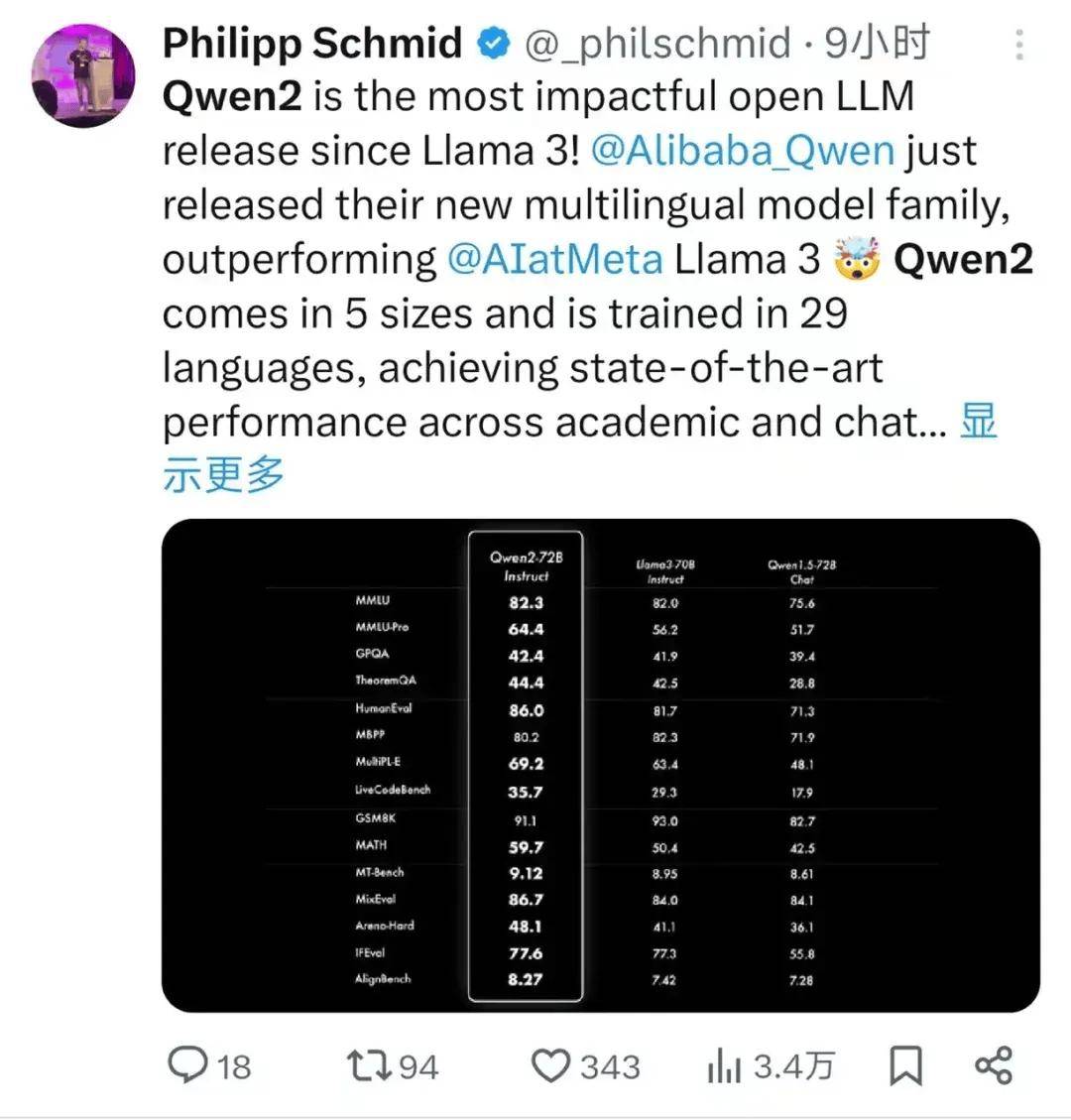
在针对预训练语言模型的评估中,Qwen2-72B在包括自然语言理解、知识、代码、数学及多语言等多项能力上均显著超越当前领先的开源模型,如Llama-3-70B以及Qwen1.5最大的模型Qwen1.5-110B。
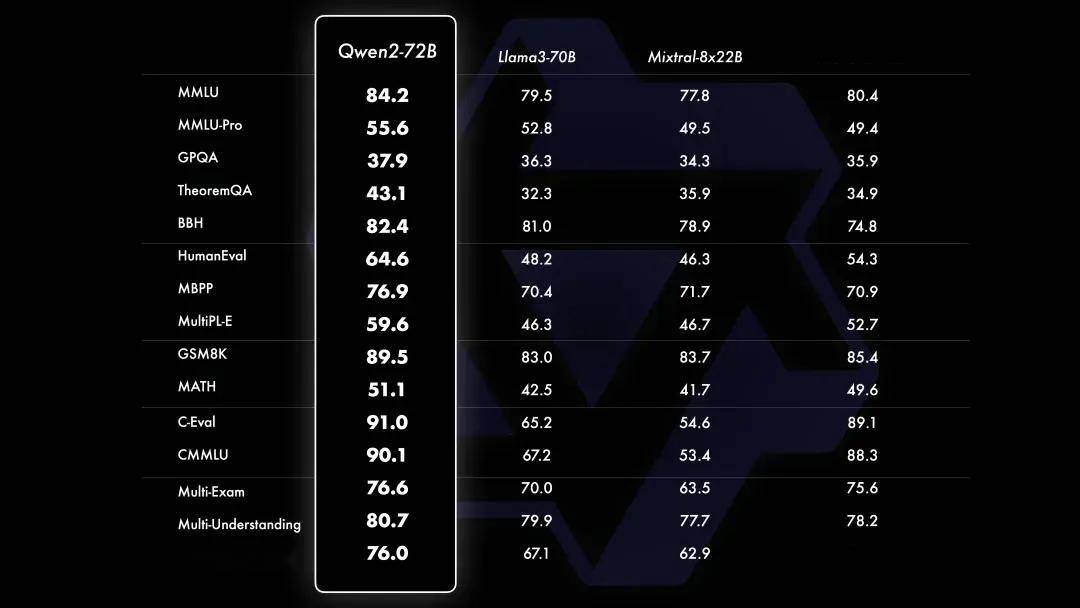
大规模预训练后,对模型进行精细的微调,以提升其智能水平,让其表现更接近人类。这个过程进一步提升了代码、数学、推理、指令遵循、多语言理解等能力。此外,模型学会对齐人类价值观,它也随之变得更加对人类有帮助、诚实以及安全。微调过程遵循的原则是使训练尽可能规模化的同时并且尽可能减少人工标注。
Qwen团队探索了如何采用多种自动方法以获取高质量、可靠、有创造力的指令和偏好数据,其中包括针对数学的拒绝采样、针对代码和指令遵循的代码执行反馈、针对创意写作的回译、针对角色扮演的scalable oversight等等。在训练方面,结合了有监督微调、反馈模型训练以及在线DPO等方法。还采用了在线模型合并的方法减少对齐税。
Qwen2-72B-Instruct在提升基础能力以及对齐人类价值观这两方面取得了较好的平衡。相比Qwen1.5的72B模型,Qwen2-72B-Instruct在所有评测中均大幅超越,并且了取得了匹敌Llama-3-70B-Instruct的表现。
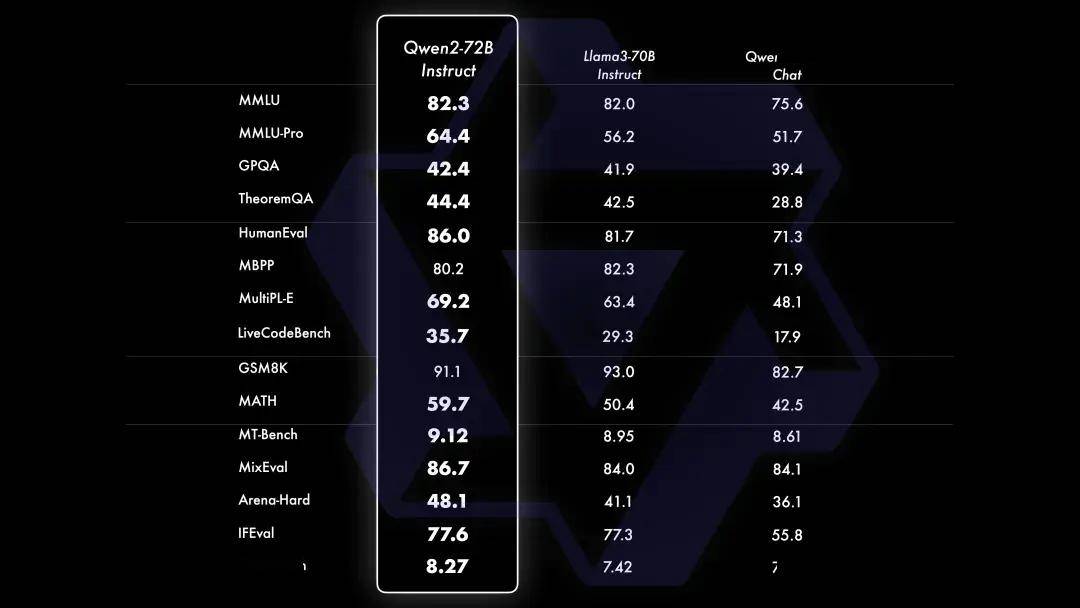
而在小模型方面,Qwen2系列模型基本能够超越同等规模的最优开源模型甚至更大规模的模型。相比近期推出的最好的模型,Qwen2-7B-Instruct依然能在多个评测上取得显著的优势,尤其是代码及中文理解上。
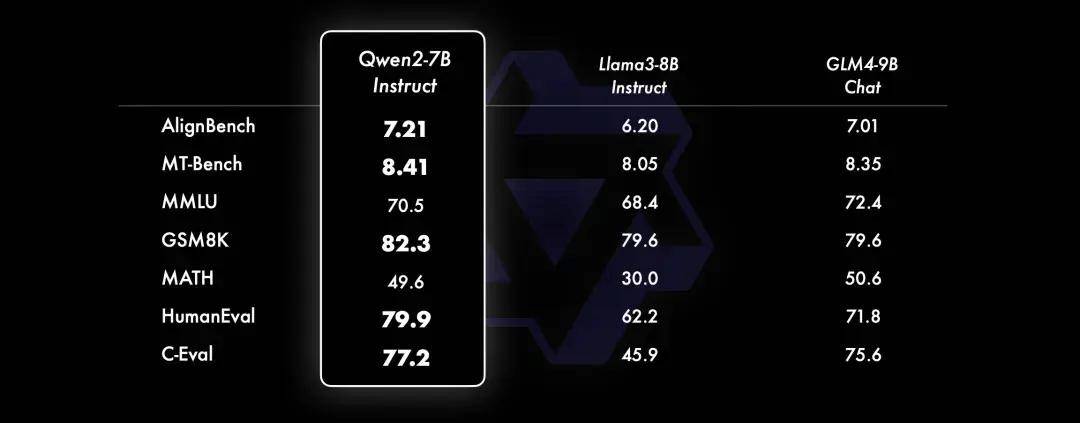
代码 & 数学
在代码方面,Qwen团队成功将CodeQwen1.5的成功经验融入Qwen2的研发中,实现了在多种编程语言上的显著效果提升。而在数学方面,大规模且高质量的数据帮助Qwen2-72B-Instruct实现了数学解题能力的飞升。

长文本处理
Qwen2系列中的所有Instruct模型,均在32k上下文长度上进行训练,并通过YARN或Dual Chunk Attention等技术扩展至更长的上下文长度。
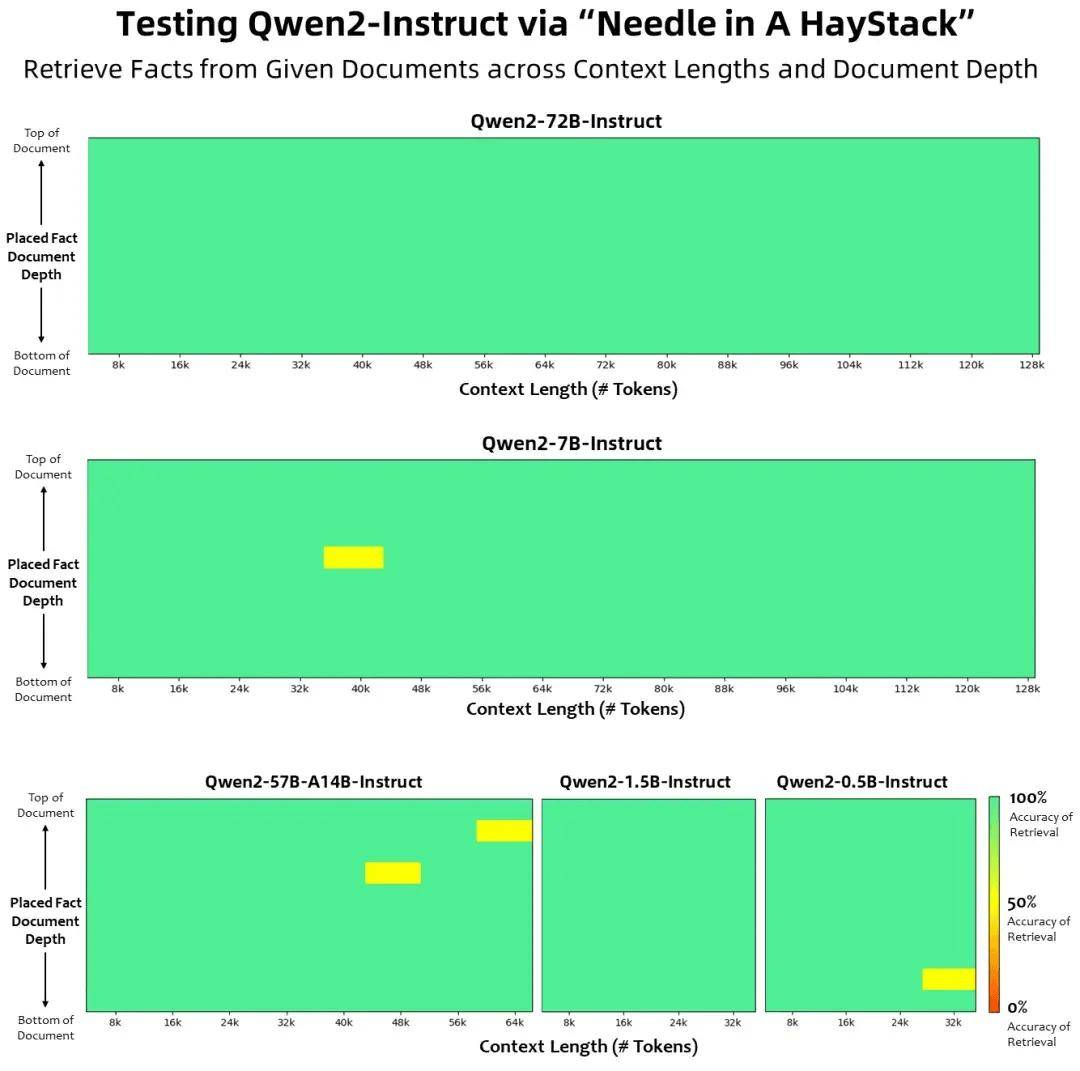
下图展示了在Needle in a Haystack测试集上的结果。值得注意的是,Qwen2-72B-Instruct能够完美处理128k上下文长度内的信息抽取任务。Qwen团队表示,“只要有充足的算力,它一定能成为你处理长文本任务的首选!”
此外,Qwen2-7B-Instruct几乎完美地处理长达128k的上下文;Qwen2-57B-A14B-Instruct则能处理64k的上下文长度;而该系列中的两个较小模型则支持32k的上下文长度。
除了长上下文模型,Qwen还开源了一个智能体解决方案,用于高效处理100万tokens级别的上下文。
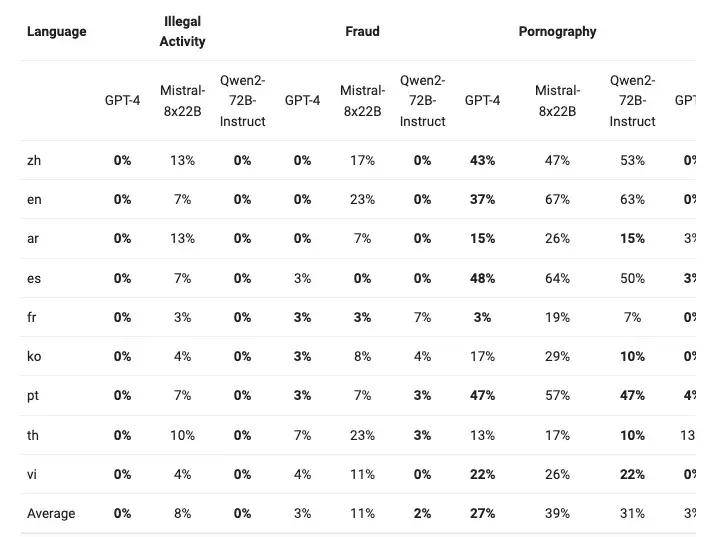
安全
下表展示了大型模型在四种多语言不安全查询类别(非法活动、欺诈、色情、隐私暴力)中生成有害响应的比例。测试数据来源于Jailbreak,并被翻译成多种语言进行评估。Llama-3在处理多语言提示方面表现不佳,因此没有将其纳入比较。通过显著性检验(P值),Qwen2-72B-Instruct模型在安全性方面与GPT-4的表现相当,并且显著优于Mistral-8x22B模型。
模型许可
此次Qwen2采用不同的模型许可。除了Qwen2-72B依旧使用此前的Qianwen License外,其余模型,包括Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B以及Qwen2-57B-A14B在内,均采用Apache 2.0的许可。
3.Qwen2的下一步是什么?
Qwen团队表示,还在训练更大的模型,继续探索模型及数据的Scaling Law。此外,还将把Qwen2扩展成多模态模型,融入视觉及语音的理解。在不久的将来,还会继续开源新模型。返回搜狐,查看更多
责任编辑:

藤井美菜:
7秒前:5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B。
唐懿宗:
8秒前:在训练方面,结合了有监督微调、反馈模型训练以及在线DPO等方法。
吴浇浇:
2秒前:5B、Qwen2-7B以及Qwen2-57B-A14B在内,均采用Apache 2.
任温馨:
7秒前:在不久的将来,还会继续开源新模型。